
Parse Czech documents
instantly
Two specialized tools for Czech digital workflows — extract transactions from bank statement PDFs, or read structured data from photos of Czech identity documents (občanský průkaz, řidičský průkaz, EHIC).
Live demo
From PDF to structured JSON
Every transaction parsed — dates, amounts, counterparty accounts, VS/KS/SS payment symbols — in under a second.
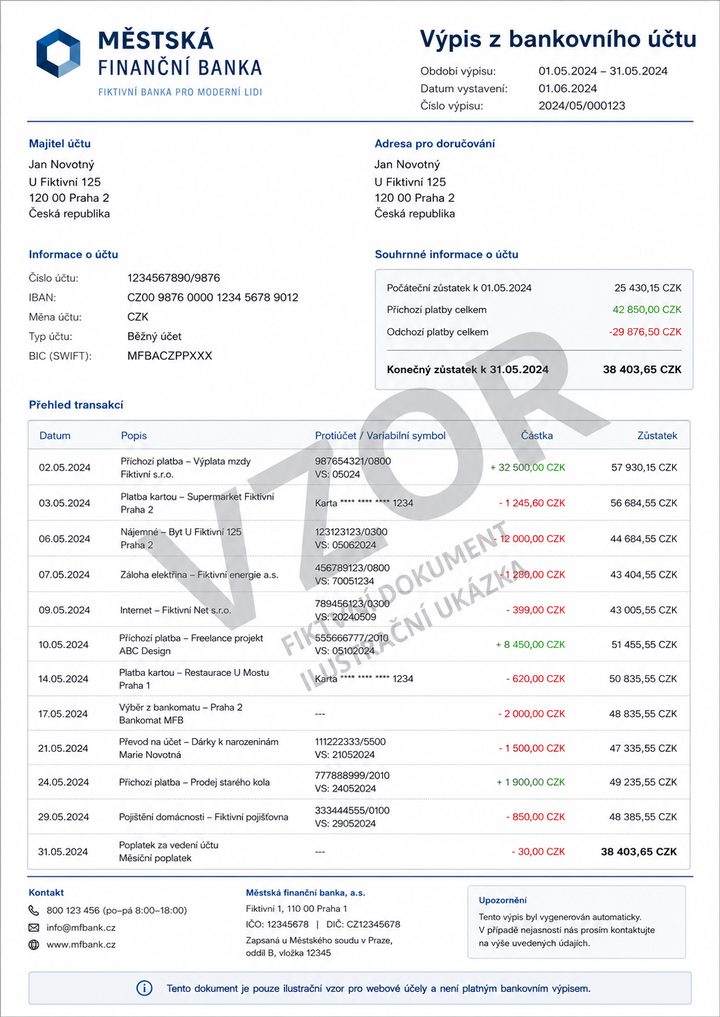
Live demo
From photo to verified fields
Every field read from the card — surname, given names, birth date, document and personal numbers — cross-checked against the MRZ.

Ready to integrate in 5 minutes
One endpoint, Bearer auth, multipart file upload. Pick your stack:
curl -X POST https://api.ginibooster.cz/api/v1/bs_parse \ -H "Authorization: Bearer YOUR_API_KEY" \ -F "file=@statement.pdf"
import requests with open("statement.pdf", "rb") as f: r = requests.post( "https://api.ginibooster.cz/api/v1/bs_parse", headers={"Authorization": "Bearer YOUR_API_KEY"}, files={"file": f}, ) print(r.json()["result"])
Supported banks










How it works
Upload your PDF
Select a bank statement PDF from any of 10 supported Czech banks. The file is processed securely.
Automatic bank detection
The parser identifies the bank, extracts all transactions, and normalises dates, amounts, and payment symbols (VS, KS, SS).
Signature verification
The embedded PDF digital signature is checked — cryptographic integrity, signer identity and trust chain. Any tampering or wrong signer is flagged immediately.
Get structured JSON
Download or copy the result. Transactions are auto-tagged — salary, social payments, gambling and more.
Upload a photo
Take a photo of a Czech identity card (Občanský průkaz) — front or back side. JPG, PNG and WEBP are accepted.
On-server field extraction
All OCR runs on our own servers — no third-party AI is contacted. The pipeline detects orientation automatically and cross-validates the MRZ code on the back side.
Get structured data
Receive name, date of birth, document number, personal number and all other fields as structured JSON.
Frequently asked
What file formats and sizes are supported?
Do I need to register to try it?
Which banks and documents are supported?
How accurate is the parser?
More from Ginibooster

Scoring LAB
We design and tune custom scoring models for your data and underwriting processes — the natural next step after pulling customer information out of their documents.
Visit Scoring LABContact
Let's discuss how Ginibooster could fit your workflow.
Tell us about your use case, integration needs or a document type you want us to support — we usually reply within one business day.
info@ginibooster.com